FREQUENCY AND VOICE ANALYSIS THERAPY
Voice Analysis and Therapy: Method of Choice for Human Biometrics
Voice Analysis and Therapy is the method of choice for measuring human biometrics. By now, almost everyone knows that everything is a vibration…that the things that make up reality are vibrating at different rates relative by frequency, or the number of times they vibrate per second. This fact, of course, has led to the idea that these vibrations can be measured and analyzed by various means and therefore used to modify, change or even transform the things that they make up.
Over the years many different methods have been developed to effect change on human bodies, minds and spirits using light, sound, color, aroma, tactile vibration and other forms of sensory stimulation. Voice Analysis and Therapy can be useful for any of these sensory therapies. (See the Vibrational Science Library on the InnerSense website for additional information about sensory science).

Frequency analysis of human biometrics has been around for decades. Brainwaves, heart rate/variability, and other measures of metabolic rate are better known than the lesser known and understood analysis of the voice. However, it’s turning out that voice may be the biometric of choice for identifying who a person is and what they want. After all, it’s the mechanism the universe gave us to say who we are and what we want. Commonly used in forensic science, security and vocal coaching, analysis and diagnosis of the human voice has become all the rage in sound, music, vocal and other forms of vibrational therapy in recent years even though it’s been brewing since the early 90’s.
Various theories have arisen over the years resulting in the development of methods, protocols and devices for myriads of applications like physical and mental status, nutritional evaluation, emotional catharsis, motivation and others. The purpose of this paper is to sort out these different protocols to create a standard of reference for therapists with regard to vibrational signatures.
Voice Analysis and Therapy Basics
To begin, it’s important to understand the basic microstructure of sound and light waves. They travel through mediums in different modes of vibration, either back and forth or straight forward, but otherwise are virtually the same. Frequency is only one of the factors in waveform analysis and synthesis. Phase and Amplitude play an equal role in describing a wave which together define the Waveshape…the actual architecture of the wave.

Single sine/cosine wave shapes are simple to understand and illustrate…being just the familiar simple gently sloping curve occurring over time. Frequency is also easy to grok. It’s just the cycles or number of waves per time period. In the image above, there are three wave peaks occurring across a time span of three seconds, in other words…one cycle per second or one hertz (1hz). In the image, Amplitude presents as the height or power of the wave.
Complex waves are more complicated to understand and diagram. Sound engineers are taught that complex waves are made up of a series of simple sine waves. The truth is though that these single wave components are either a sine wave, cosine wave or some combination thereof, which controls the Phase of the signal, or how it peaks over time.

This leads to an entire new science of universal automata where the cosine and sine waves become the actual and potential components that create the waveshape. Called real and imaginary, these automata are the smallest most indivisible components of all reality, and represent the most primal, fundamental level of reality, beyond frequency and sacred geometry…in fact, they make them both. But that, along with Phase is another story altogether that you can read more about on the blogs and papers on our website at www.innersense-inc.com. Voice Analysis and Therapy utilizes all of these components of the voice wave.
Biofeedback of Voice Analysis and Therapy
Whereas phase and amplitude have become the main focus of research and development at InnerSense, accurate and precise voice analysis and feedback is vital as a starting point especially when it comes to performing sound therapy with it. Even though frequency is just one of the main characters of waveforms, no accurate analysis can be made without the ability to accurately and precisely measure it in a human biometric or produce it for biofeedback.
Scientists measure frequency in Hertz, or cycles per second. There’s a difference between a simple frequency, complex frequency and a fundamental frequency.
- A simple frequency is a single frequency of a specific hertz like 261.63 Hz, the cycles per second that represents middle C on a piano at A440 in 12-tone equal temperament.
- A complex waveform is a combination of simple, single frequencies stacked together in some relationship with a given fundamental or root frequency.
- A fundamental frequency is a single frequency that represents the lowest frequency of a complex wave that contains a full set of harmonic overtones based on multiples of the fundamental with the exception of higher dimensional resonators such as bells, singing bowls and gongs. This would also cover the Schumann Resonance. All other partials are noise and completely unrelated to the fundamental.
Simple frequencies (sine and cosine waves) are usually made with frequency generators that can produce specific cycles per second. Complex frequencies are produced from the human voice, musical instruments or other natural or synthetic sounds and even noise.
Even though most people know by now that everything is vibrating at different frequencies, the other two main components, phase and amplitude, are not so well-known or understood. Amplitude, is perhaps better understood, but not in terms of the psychoacoustic properties of amplitude envelope relationship to emotions through Sentics.
Unfortunately, in order to find out what’s right, the harmonic signature must be gathered, and that’s been impossible to date because current systems take timed samples and then average the results. This method provides the mean or average value, which has little to nothing at all to do with the so-called fundamental frequency. This is the essence of the voice analysis and therapy of the Fundamentalizer.
Complex waves like those of the human voice consist of a fundamental frequency and a series of harmonic overtones that are whole number multiples of it. Each partial that makes up the whole is either a sine-wave, cosine wave or combination thereof.
However, the human body is like an instrument that vibrates across a really wide range of frequencies. The human voice, for example, traverses a broad band of the music scale. The highest frequency on record is G10 or 25kHz by Brazilian singer Georgia Brown in 2004 and the lowest is G-7 or 0.189Hz, eights octaves below the lowest G on a piano, for Tim Storms in 2012; so, at the extremes, a full 17 octave range!

This is one of the reasons that finding the fundamental frequency of a biometric signal is so difficult…human signals float around within a range of frequencies and rarely stay on the same frequency for very long. In order to resolve this issue, timed samples are taken and averaged, thereby discarding all of the harmonic data present. The only way to accurately identify a natural harmonic fundamental frequency is to identify the lowest frequency of the human voice that has a complete whole number harmonic overtone series. This is what occurs in the voice analysis and therapy utilizing the Fundamentalizer.
All other components of the signal are noise with the exception of certain forms of sibilance. This causes a major problem in voice analysis and feedback…without the fundamental frequency it is impossible to see the harmony within a signal. The mean or average frequency shows where the middle of the scale is, but that means little regarding the true harmonic signature of the signal. Two frequencies of 100 and 200 Hz. average to 150 Hz., which has nothing to do with either.
However, if “wavelet” theory is applied it’s possible to observe the crossover points and procession of peaks in the partials and find the true fundamental frequency.
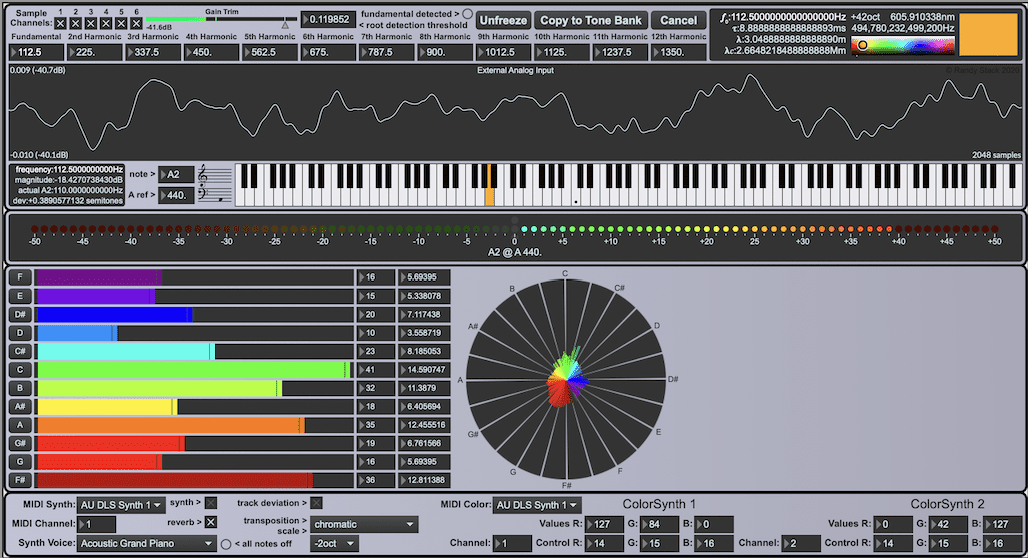
Figure Three shows true fundamental frequencies being generated by a human voice in real time. Simultaneously, it is showing the real time pitch and notating it on manuscript paper while indicating its note’s position on a 140 key piano keyboard. The sound frequency is instantly converted into its correlated light and color, which can output to a computer screen, wall, ceiling or other surface with a projector or MIDI color synthesizer. Once frequency accuracy has been verified, phase and amplitude can be measured and analyzed in complex waves.
Frequency in Voice Analysis and Therapy
Although a proper frequency analysis is required as the starting point to identify an individual’s personal vibrational signature, it’s extremely limiting to rely on frequency alone because of difficulties inherent in its accurate capture, analysis and method of reproduction due to:
1. Human beings are like music instruments whose brain, heart and voice frequencies vary across a very wide range of frequencies. Without knowing which overtones are related it’s impossible to see the harmony in the signal. To accomplish this the true fundamental frequency must be found and that cannot be done with a timed sample that has been averaged, which only provides the mean or average. True mode can only be ascertained by real-time measurement of the specific frequencies rather than quantizing the signal to musical notes. This is way it is done with the voice analysis and therapy of the Fundamentalizer.
2. In frequency analysis, the unit of measurement chosen must be a function of the sampling rate used to take the sample. For example, frequency is measured in Hertz (Hz.) or cycles per second. Therefore, any sampling rate must reduce down to 1 cycle per second in the zero octave to be accurate. Most systems available report in semitones not hertz, so they can be off as much as 7.2 Hz from 248.8 to 256 Hz and 7.5 Hz between 256 to 263.5 Hz. At the high end of a female soprano voice the measurement can be off as much as 25.7 Hz!
3. The human voice has particular vowel formants that are tied to the particular dialect they area using. A formant is the spectral shaping that results from an acoustic resonance of the human vocal tract.[1][2] Therefore, when people utilize more of one vowel than another it shifts the frequencies toward those formants. For American English the formants are:

4. In reproduction the relative phases of all harmonics of the fundamental must be maintained. It is impossible to start separate light, sound, color and vibrational generators at once so that the peaks of each of partial remains in phase. All generators must be run and maintained in a fully phase-synchronous manner for phase relationships to be preserved and transmitted. The only way to do that is to utilize a continuous phase synchronization monitoring and adjustment algorithm, which resynchronizes each and every oscillator when any change is made to any parameter of any single oscillator.
5. There’s a lot of discussion these days about whether samples should be taken and reproduced by analog or digital means. The truth is that each has advantages and disadvantages. Analog devices are generally considered superior because they analyze and reproduce the true waveform of a signal whereas digital provides only an approximation of the original due to the missing pieces created by the intermittent sampling of the signal instead of including the continuous wave.
However, research has shown that digital may be the method of choice because it’s faster, more accurate and precise regarding frequency and can be controlled a lot easier…not to mention much less expensive. Analog frequency analyzers that offer phase, amplitude and temperature control are many tens of thousands of dollars because of the need for lock-in amplifiers and environmental regulators that just don’t exist on simple machines.

As an example, a Sawtooth wave consists of all even and odd harmonics. However, a classic Square Wave is composed of only odd overtones. In a digitally produced square wave the sharp edges and abrupt 90˚ turns at the time transitions along the wave that creates a hard, transient sound that can be dangerous to speakers and transducers. These artifacts result in noise and sometimes clipping, whereas the analog version has a smoother transition that is more leveled out and spiraled creating a more natural flow between the curves of the wave.

Until recently it was impossible to create digital waveshapes that are identical to analog versions. However, with tools like Fourier additive synthesis and polynomial transition region algorithmsthe architecture of the wave can be controlled and digital signals can become more natural-like. Below is a square wave produced using Fourier additive synthesis on a Sensorium LSV III system.

The transition zones of this digital wave are more or less identical to the natural analog wave shown in figure five. All things considered, polynomial digital is now the preferred method due to cost, ease of use, accuracy and reproducibility. The Fundamentalizer section of the Sensorium III utilizes both polynomial and Fourier synthesis for voice analysis and therapy.
So, the bottom line is that relying solely on frequency for Voice Analysis and Therapy is not preferred because of the inability to determine the harmonic architecture, sample rate issues, and frequency formants.
Part Two Continued in the Next Blog